关于RAG的深度思考
本文从RAG的定义、价值、实现多维度分析思考,主要面向于基于切块的RAG方案,对于知识图谱、知识超图这种立体化知识结构,本文做不过分讲解。
由于比较懒,有空就会不断完善后面的敷衍内容。每每写文章,本有长篇大论,但是写着写着觉得好像也没必要(应该不是懒了),于是就小几千字,从未过多。(下次拿代码占字数)
本文思路
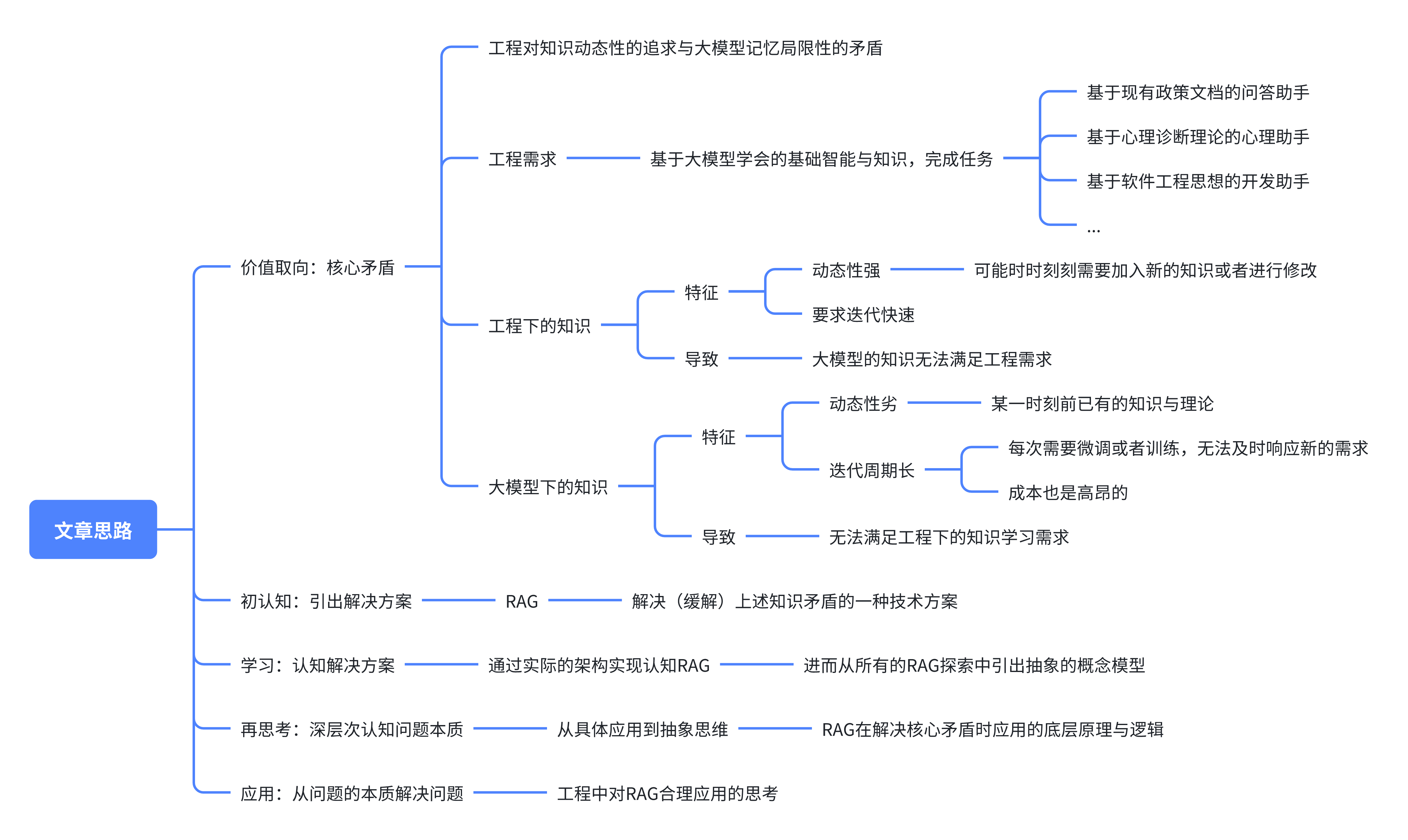
RAG是什么?
少讲定义。
检索增强生成(RAG)就是在大模型解决问题时,帮它检索出可能需要用的到信息,然后让大模型可以更好的思考与解决问题。
为什么需要RAG?
大语言模型无法快速地进行模型迭代,导致无法及时、动态地学习知识。
小故事例子
存在一个巨无霸公司,这个公司内部每天都在产生上百篇文档,为了方便公司内部员工的阅读,老板基于原来的上万篇文档微调了一个大模型,然而如果对后续的文档继续微调的话无法满足该公司文档的每天海量更新,周期长、成本高。
某一天,这个公司里的小李发现,直接把一篇较短的文章发送给大模型聊天助手,它是可以根据对话上下文进行文章的解读工作的,即,可以认为大模型对上下文内的内容有一定的记忆、学习与理解能力。
于是小李心想,把所有文档投在大模型的上下文里不就用不着微调了吗?但是很快他发现大模型的上下文是有限地,一般来说投入几十万字的文档它就无法学习了!这怎么办呢?
于是他想了个妙招,既然大模型的能学习上下文记忆但上下文是有限的,那他每次放一部分与想问的问题相关的文档不就可以了吗?本质上公司就是希望使用大模型来解决文档臭长臭长,没人愿意读的问题。
在尝试后,他通过编排把文档按照业务场景分类标注,比如在问服务器问题时,他就会选择几篇自己觉得最靠谱、最相关的文档投给大模型,然后再咨询大模型自己的问题,让大模型学习文档内容来协助解决问题。
过了一段时间,他发现这个方法确实有效,然而,人哪有这么多功夫去整理文档呢?更何况问的时候还要去动脑子找哪些文档是相关的!人能懒着,为什么要动脑子?不行,小李觉得自己就是为了偷懒才要用大模型,结果还要伺候它,给它找文档!天理难容。
小李趁着摸鱼的时间,发现传统的自然语言处理领域有一种把文本转化为向量的方法,通过一个AI模型把文本转化为与其语义对应的向量数据,就可以通过传统矩阵计算的方式,判断文本之间是否语义有关联度。
顺势一想,不难想到,直接把所有文档都向量化,然后存在一个可以存储和检索向量的数据库里,在问大模型问题时,就可以由程序来通过向量计算判断每一个文档与用户问题的关联度,进而检索到高关联度的文档给大模型学习。
好方法!但是很快小李发现Text Embedding Model(即上文提到的文本向量化模型)的上下文也是有限的,这就让整篇文档无法直接被向量化。小李干脆就按照段落切割文档,分为一个个文档块,然后向量化,并存储在向量数据库里。
他又写了一套程序,可以让用户输入问题,然后自动向量化并检索到最相关的二十个文档块,然后把问题和文档块都给大模型,由大模型来解读。
这一套程序一经在公司内部公开,就广受好评,很快小李在技术部门连升三级。
RAG解决了什么问题?为什么能解决?
通过小李的例子,可以看到RAG就是为了解决(改善)大模型知识的低成本、动态学习问题。
RAG的基础能力条件:
- 知识学习:大模型能根据上下文记忆进行一定程度上的学习与理解
- 知识检索:文本可以被转为语义相关的向量,进而让机器可以快速进行基于语义相关度的文本检索
- 知识存储:人类的文档虽然很长,但是存在段落等特征,可以被切分为一块块的基础知识块,进而进行向量化并存储在向量数据库
实际上就和人一样,要在淘宝当客服,你得有脑子(生物意义上,不是骂人啊),至少可以理解文档写的啥、能通过电脑找到你觉得语义上相关的文档。至于知识存储,自有运营在电脑上放相关文档文件,并用文件夹分类方便客服来查找。
常见的RAG实现方式
见参考资料,不再复制粘贴,赘述不已。
求同存异:不同RAG的设计逻辑
知识存在的特征
不同RAG的实现逻辑差别之一是,针对知识切块的角度不一样。
人亦云:“改编不是乱编,戏说不是胡说。”
由人之云可知,文档切块是让你尽可能完整文章原意地切块,而不是让你切块之后成和打碎的糖果一样,碎成渣了,不知本来长啥样。
因此,我们常说要根据语义来切块,要根据文档的内容结构来切块。本质上,是要分筋错骨,顺着知识的体系切块,就像顺着肉的筋脉切肉,才能少费功夫且保证肉是完整有口感的。
举点例子:
- Markdown格式文档的切分要以各级标题为结构,按照各级标题划分的结构来切块
- 有目录的文档也同理,按照目录来切块
- …
哎,其实可以发现,如果说程序是数据结构+算法,那么知识就像是知识结构+内容。我们要顺着知识的筋脉(目录)走,按照筋脉(目录)来切分知识文档内容。
因为,从宏观语义上来看,大部分目录会把两个联系不紧密的内容分隔开,这也是我们这么切的原因之一。其他原因还请读者在实践中逐步体验,笔者目前经验不足,难以形成准确的语言描述。
知识的检索形式
不同RAG的实现逻辑差别之二是,针对知识检索的角度不一样。
同知识的特征,不同形式的知识,在存储上也有不同的存储方式考量。
举点例子:
- Markdown、有目录的文档,因为有结构化的内容,可以通过
标题+内容的形式检索,当然也可以先通过目录来定位块大致位置,再语义检索 - 无目录的文档,直接通过语义检索;或者,既然你没显式的结构,那就从知识实体和知识联系的角度,把你切碎,在拼接为知识图谱,按照图的形式进行检索
- …
检索形式的不同是针对知识结构的形式和存储方式不同,设计出更高性能、更高准确率的检索方式。
思考:RAG的底层原理与逻辑
对知识的切分和检索,是试图把知识最小原子化(语义不能变),以积极适应大模型上下文学习量有限的问题。
工程中对RAG合理应用的思考
想一想RAG到底是个啥?文本检索方案?大模型的知识库?大模型的长期记忆检索方案?
从RAG的特征出发,该怎么在工程中合理应用,该应用在工程的哪里?
RAG架构的选择:后宫三千,仅取何人?
根据文档的内容结构形式和业务场景需要的准确率来选择。
工期与结果:准确率要多高才是高?
俗话说:“RAG做Demo一周,上线调优一年。”
不要想着一口气吃个胖子,根据业务场景先确定一个最低的准确率,然后不断根据新增知识的形式调整即可。
大部分需求没那么高的准确率要求,同时准确率越高,提升1%所需的成本会急剧增加,此时与其考虑准确率不如思考如何从交互或者提示词上优化,让用户体验更好一些。
参考资料
- 标题: 关于RAG的深度思考
- 作者: xiue233
- 创建于 : 2025-04-11 22:30:40
- 更新于 : 2025-05-03 22:46:38
- 链接: https://xiue233.github.io/2025/04/11/deep-thought-of-rag/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。